
Chaos-pass replaces tests-pass
After the soak fixes settled, the cluster ran flat for a week. CPU bounded, RAM bounded, peer counts stable, no nodes silently eroding. That's a green light for "the substrate works at idle," not for "the substrate is shippable." A control-plane substrate that only behaves under steady-state is the kind of thing you discover is broken six hours into an incident, when a single broker has been flapping and the rest of the cluster can't decide if it's dead.
So this week I pointed the chaos battery at it.
The principle
Sprint 02 of this project locked Golden Principle #5: chaos-pass replaces tests-pass. The idea isn't novel — Netflix put Chaos Monkey in production a decade ago, Jepsen has been making distributed systems vendors look bad since 2013. The novel part for this substrate is that the chaos battery is the same harness regardless of which feature sprint is running. Every sprint's exit criterion has to be "the existing tests pass under chaos," not "the existing tests pass."
That gives you a forcing function. A test that's green at idle but flaky under PartitionPair is broken, not flaky — the substrate has a real failure mode you're now choosing to ignore. The chaos battery is what stops you from ignoring it.
The primitives
The chaos crate (crates/mesh-chaos) ships thirteen primitives. Each one is a Rust struct implementing ChaosPrimitive with three things: an apply() that does the damage, a revert() that puts things back, and a detect() that tells the test framework what evidence to look for in the OTLP spans to confirm the substrate noticed.
| Primitive | What it does | What it surfaces |
|---|---|---|
KillNode | SIGKILL one node | Connection-drop detection; staleness pruner |
RestartNode | Kill + respawn same identity | Reconnect path; ghost-connection cleanup |
BurstKill | Kill multiple nodes at once | Quorum/membership behavior under sudden loss |
WedgeNode | Pause node's tokio runtime | Slow-vs-dead distinction; backpressure |
DiskFull | Fill data dir | Identity file fsync failures; graceful degradation |
PartitionPair | Break connectivity between two nodes | Spanning-tree heal; alt-path routing |
PartitionSubset | Isolate a subset from the rest | Split-brain detection; bridge survival |
FlapLink | Repeatedly up/down a peer link | Reconnect storms; idle-timeout interaction |
FirewallInbound | Drop inbound traffic to a node | Asymmetric failure; outbound-still-works case |
ClockSkew | Skew a node's wall clock | Staleness comparison robustness |
NatShift | Simulate NAT remapping | iroh's hole-punch re-establishment |
SlowLink | Add latency to a link | Backpressure; head-of-line blocking |
LossyLink | Drop a % of packets on a link | Plumtree's IHAVE retransmit path |
Eight of those have corresponding test files (tests/chaos/*.rs). The other five are in the harness but not yet wired into named tests — they're available for ad-hoc cluster torture.
The run
I bootstrapped 18 nodes — the standard 2-mesh layout, with bridges — and pointed the test runner at the chaos battery. The admin-ui Tests tab is where I watched the results land.
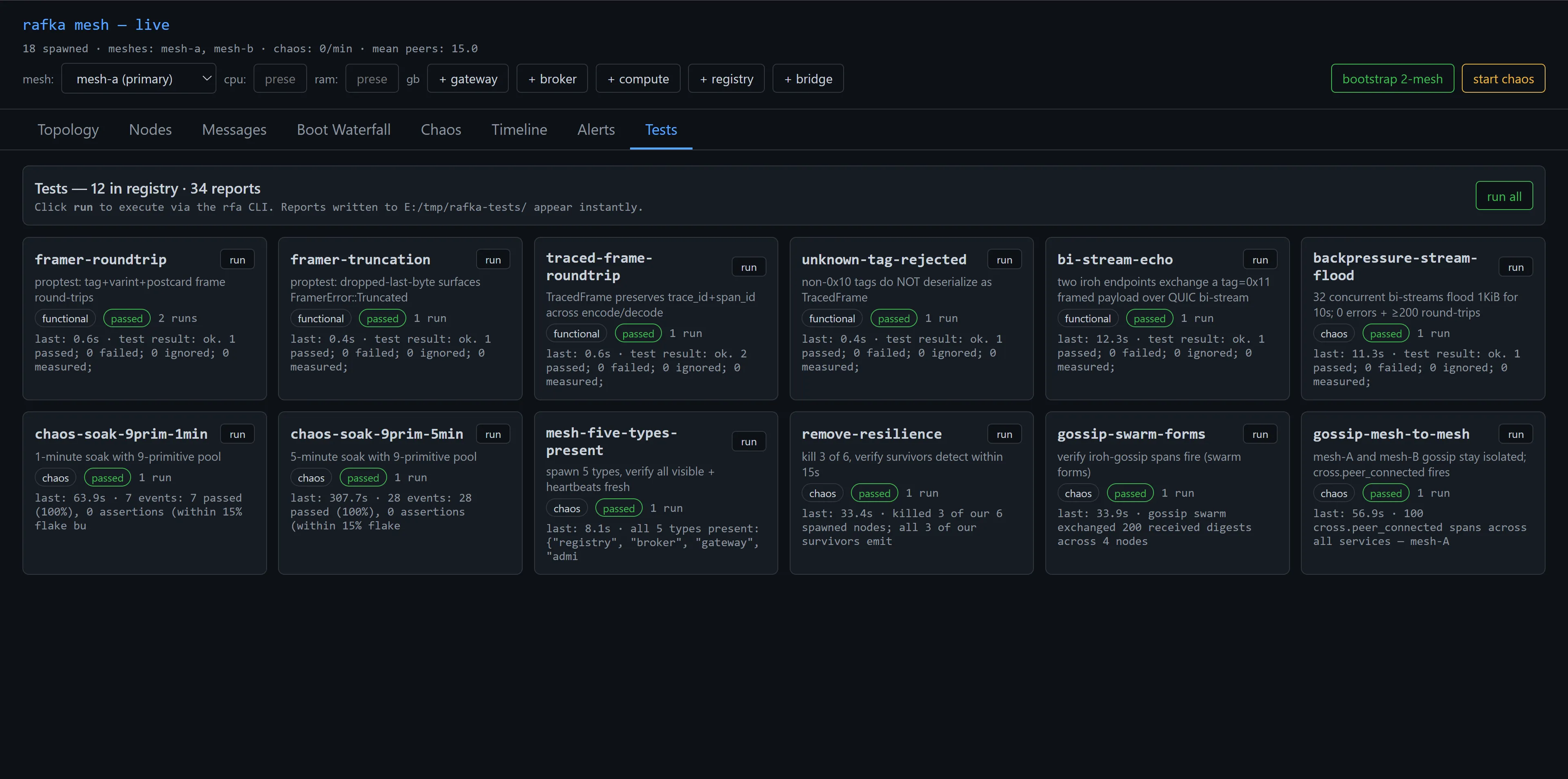
The numbers worth pulling out of that grid:
chaos-soak-9prim-5minran 307.7 seconds, fired 28 chaos events, all 28 passed within the 15% flake budget. That's the headline test — 5 minutes of continuous random chaos, the substrate doesn't fall over.remove-resiliencekilled 3 of 6 spawned nodes and verified all 3 survivors continued emitting heartbeats. The substrate notices, prunes the dead entries, keeps going.gossip-swarm-formsasserts that after a clean boot 4 nodes exchange ≥200 gossip digests within 34 seconds. That's the basic "Plumtree is actually doing its job" test.gossip-mesh-to-meshverifies that 100mesh.cross.peer_connectedspans fire across all services within 57 seconds — proving the bridge architecture actually bridges.backpressure-stream-floodfires 32 concurrent bi-streams of 1 KiB payloads for 10 seconds. 200+ round-trips, 0 errors. The data plane survives concurrent load.
What chaos catches that integration tests don't
The interesting one to me is the gap between the functional tests on top (5 of them — framer round-trip, frame truncation, traced-frame, unknown-tag rejection, bi-stream-echo) and the chaos tests on the bottom (7 of them, all chaos-tagged).
A functional test like framer-roundtrip answers "does the framer encode and decode correctly when nothing else is going on." That's necessary. It is not enough. The framer also has to be correct when the surrounding QUIC connection is being killed by KillNode, when the receiving node is being wedged by WedgeNode, when packets are being dropped by LossyLink. The chaos tests run the same framer code against those conditions.
backpressure-stream-flood is the cleanest example. The flood test by itself would catch "can the substrate do 200 round-trips in 10 seconds." It can. The chaos-tagged version of the same test catches "can it do 200 round-trips in 10 seconds while three random chaos primitives are firing in the background." That's a different question.
The timeline view is where chaos-period vs. steady-period events become legible. Every peer.connected event shows up with its source and target; chaos events get their own timeline rows; you can see them interleave in real time.
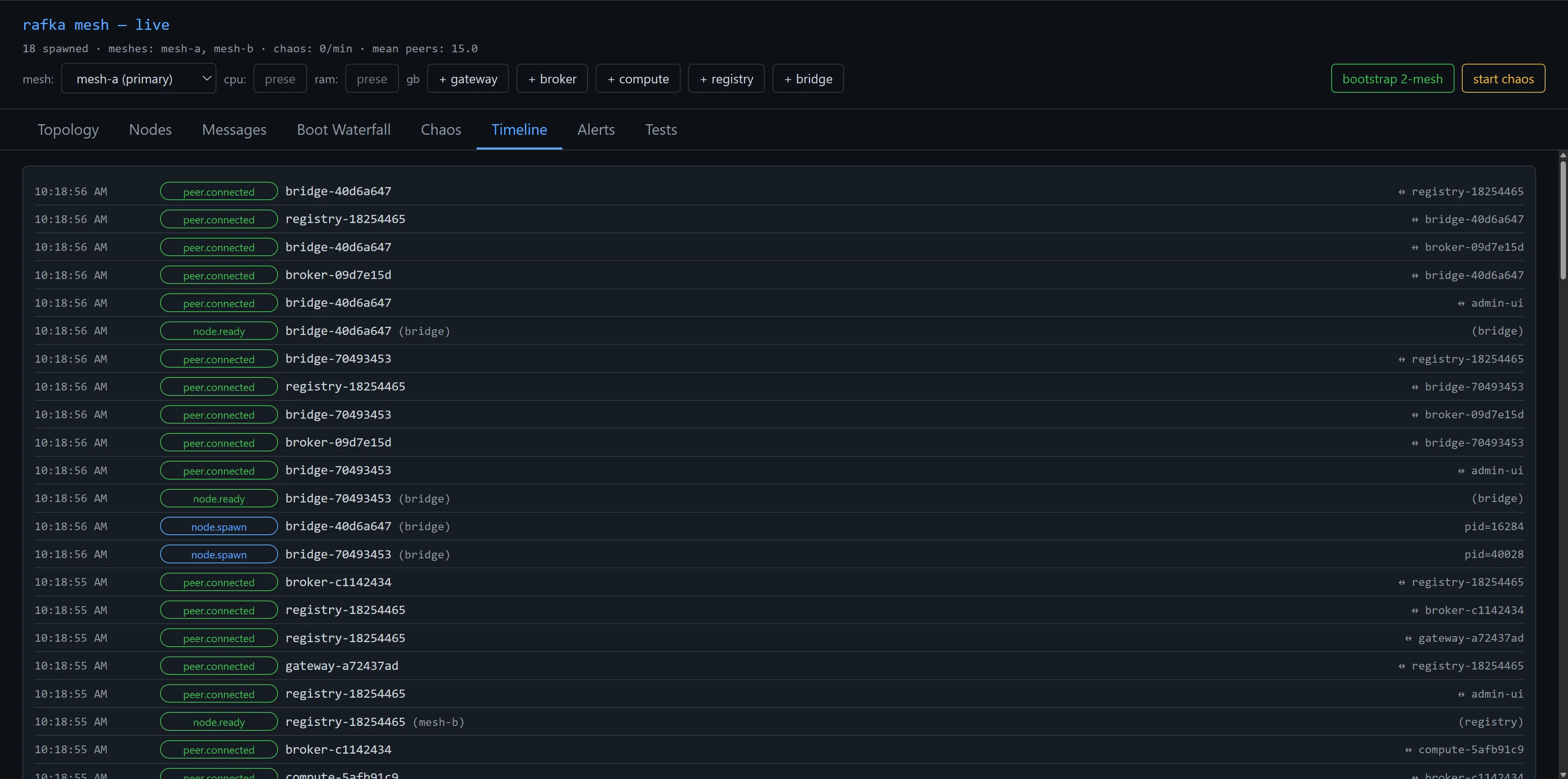
When the chaos harness fires KillNode, you see a node disappear from the timeline. Within a few seconds you see the surviving nodes re-establishing connections — peer.connected events fan out across the substrate as HyParView reshuffles the active view. The chaos worked; the substrate responded; both are visible.
What I'd tell a team
- Steady-state is the baseline, not the target. If your test suite only runs at idle, the test suite isn't done. It says nothing about how the substrate behaves under the conditions you'll actually encounter in production. Idle is the easiest case; you need the hardest cases too.
- Build chaos primitives once, reuse them everywhere. The 13 primitives in
mesh-chaosare shared between unit tests, soak runs, and ad-hoc torture sessions in the admin-ui. The cost amortizes immediately. The alternative — every test author writing their own kill-the-broker helper — gives you 5 incompatible flaky helpers and no shared vocabulary about what "broken" means. - Make chaos visible. The admin-ui's Chaos and Timeline tabs are not just dashboards — they're the operator's view of what's failing and what's recovering. Without them, "the test passed" is a green light and nothing else. With them, you can see the substrate noticing chaos, choosing to react, and re-establishing. The visibility is the test.
- Define a flake budget up front and stick to it.
chaos-soak-9prim-5minruns with a 15% flake budget — 4 out of 28 events can be allowed to miss their detection window before the test fails. That budget is what separates "we have flaky tests" from "we have a known reliability envelope." If the substrate ever runs at 50% flake, that's an architecture problem, not a test problem.
What's next
That closes the engineering arc. The next post wraps it up — the substrate is sound, the chaos battery is green, and the whole thing is going public. Open-sourcing it next week.