
Why I'm building a distributed mesh substrate in Rust
What I'm ultimately after is an event-streaming system whose nodes can sit on different networks — different cloud regions, different colos, a laptop on a coffee-shop Wi-Fi — and form a working cluster anyway. Direct-TCP-on-a-VPC isn't enough for that. The transport layer has to handle NAT traversal, identity, mesh formation, and reconnect for me. But the streaming layer is a problem for later; first I need the substrate underneath it to be sound, and this notebook is about the substrate.
I picked iroh for the substrate. QUIC under the hood, relay tier for cross-NAT, hole-punching where it can. The application layer on top is iroh-gossip — Plumtree for eager broadcast, HyParView for membership. The combination gives me a self-organizing peer set without writing any of it myself.
The first thing I'm going to do is run 18 of these on one machine and watch what happens.
Why iroh, not direct TCP
The conventional design does the simplest thing that works: direct TCP between nodes, a metadata store like ZooKeeper or etcd, every node knowing every other by hostname. That works because the nodes live in a single network where hostnames resolve and ports are open.
The deployments I want to support don't look like that. A node behind a residential NAT. A compute box in someone's homelab. A gateway in AWS. They can't reach each other on direct TCP. They CAN reach each other via QUIC + a relay, with hole-punching closing the hop where possible. That's exactly what iroh does, and I'd rather use a maintained library than build it.
What iroh buys me concretely:
- Identity from a keypair, not a hostname. Every node has an Ed25519 keypair; the "address" is the public key. The same key from any IP works.
- NAT traversal. STUN-style probing, hole-punching, relay fallback. I don't have to think about it.
- QUIC transport. Multiplexed streams over one connection, 0-RTT reconnect, no head-of-line blocking. Better defaults than tuning TCP.
- Discovery primitives. mDNS for LAN, DHT for internet-scale. Optional and pluggable.
The cost: more bytes per packet than raw TCP (TLS 1.3 framing + QUIC headers + congestion-controller state per connection). For a substrate that's going to broadcast small heartbeats, that's the right trade.
What iroh-gossip is for, and what it isn't
iroh-gossip runs Plumtree + HyParView on top of iroh's QUIC. Plumtree forms a spanning tree across subscribed peers for eager broadcast; HyParView keeps the per-node active connection set small and roughly constant (~5–7 peers regardless of cluster size). That's how Bitcoin scales to 50,000 nodes without every node connecting to every other.
The thing I want to be careful about is what I broadcast. iroh-gossip is a control-plane primitive — it's designed for "the cluster's membership just changed" or "a new topic appeared," not "here is my full state, every two seconds, forever." Bitcoin doesn't broadcast every node's status every 2 seconds. It broadcasts transactions when they arrive. Big difference.
I have a hunch this is where I'm going to get bit. I'm setting up the gossip emit to fire on a 500ms timer with a GossipDigest that includes peer counts, frame counts, CPU/RAM. That's a lot of state on a fast clock. We'll see.
The architecture, briefly
Three layers, with deliberate separation:
| Layer | Crate | Responsibility |
|---|---|---|
| Transport | crates/mesh-transport | iroh Endpoint setup, ALPN, bind addr, mDNS toggle |
| Substrate | crates/mesh-node-base | Identity, peer registry, gossip emit loop, LoadSampler (self-reported CPU/RAM via sysinfo), staleness handling |
| Telemetry | crates/mesh-telemetry | OTLP/tracing init, every node's spans land in Jaeger |
On top, five example node types — broker, gateway, compute, registry, bridge. From the substrate's perspective they're interchangeable; the type is just a string. Each one is a 10-line main.rs that calls NodeRuntime::new("type").run().await and supplies a .env.dev preset for its CPU/RAM budget.
There's also an admin-ui — a React + Vite dashboard that joins the mesh as a passive observer and renders the topology live. Hub-vs-leaf is visible in the layout. Each node card shows its CPU/RAM utilization against its declared budget. That's the surface I'll use to feel what the substrate is doing.
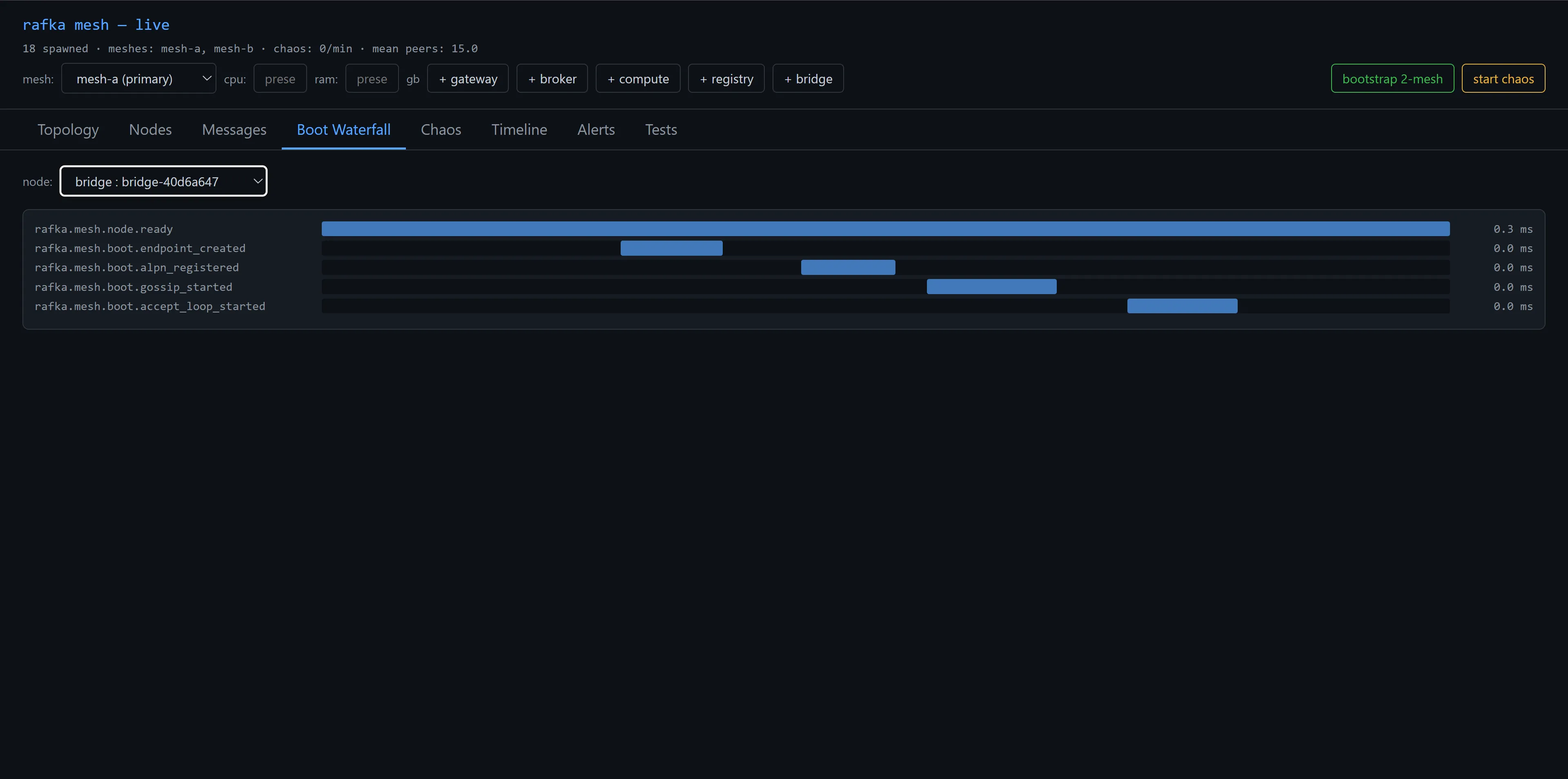
Telemetry is built in from boot. The admin-ui has a Boot Waterfall view that decomposes the spans every node fires on startup — endpoint creation, ALPN registration, gossip subscribe, accept loop. The shape of a healthy boot is five short spans nested under a mesh.node.ready root, sub-millisecond each on this machine. When something goes wrong at boot, you see which span stretched.
What I expect to break
I'm writing this down on purpose so I can be honest about the hypotheses going in:
- Gossip volume. At 18 nodes broadcasting every 500ms, that's 36 broadcasts/sec. Plumtree fans each one out across the spanning tree. I expect to find that 500ms is too aggressive for steady-state health.
- OTLP overhead. Every span we emit becomes a protobuf-encoded gRPC frame to Jaeger. If I'm not careful about what fires at what level, the telemetry will cost more than the work it's measuring.
- Connection accounting. Peers will reconnect over time. I expect there's a bookkeeping bug somewhere — registries that grow without pruning, connections that close without their tasks knowing. I haven't found it yet.
What I don't expect — and would be surprised by — is iroh itself being expensive in some fundamental way. The library is maintained by people who deal with this for a living.
What I'd tell someone starting
- Pick the substrate first. The choice of transport (raw TCP, gRPC, iroh, libp2p, …) determines everything else. Don't pick the wire format before you've picked the network.
- Don't broadcast state on a clock unless you've measured what it costs. Most "heartbeat" patterns assume small clusters, small payloads, slow cadences. Two seconds with a 200-byte digest at 18 nodes is already 36 broadcasts/sec.
- Build the dashboard first. Or at least the topology view. You're going to be looking at this thing constantly while you debug it, and a
print!doesn't compose into a mesh layout.
What's next
Tomorrow I bootstrap 18 nodes on my workstation and see what they do at idle. The plan: spawn one of each type, then 17 more, let them gossip for a minute, look at the numbers. The next post in this notebook is what those numbers were and what I did about them.