
Open-sourcing the Rust Distributed Mesh
Five weeks ago I started building a P2P mesh substrate in Rust on iroh. The point was never the mesh — it was learning what it actually costs to run one before betting a real product on it. The first canary pegged an 80-core box at 100% CPU with 18 nodes idling. The fifth week's canary holds the same 18 nodes at 5%, steady-state, through a 4-day soak.
Today I'm pushing the whole repo public.
→ github.com/drlukeangel/rust-distributed-mesh
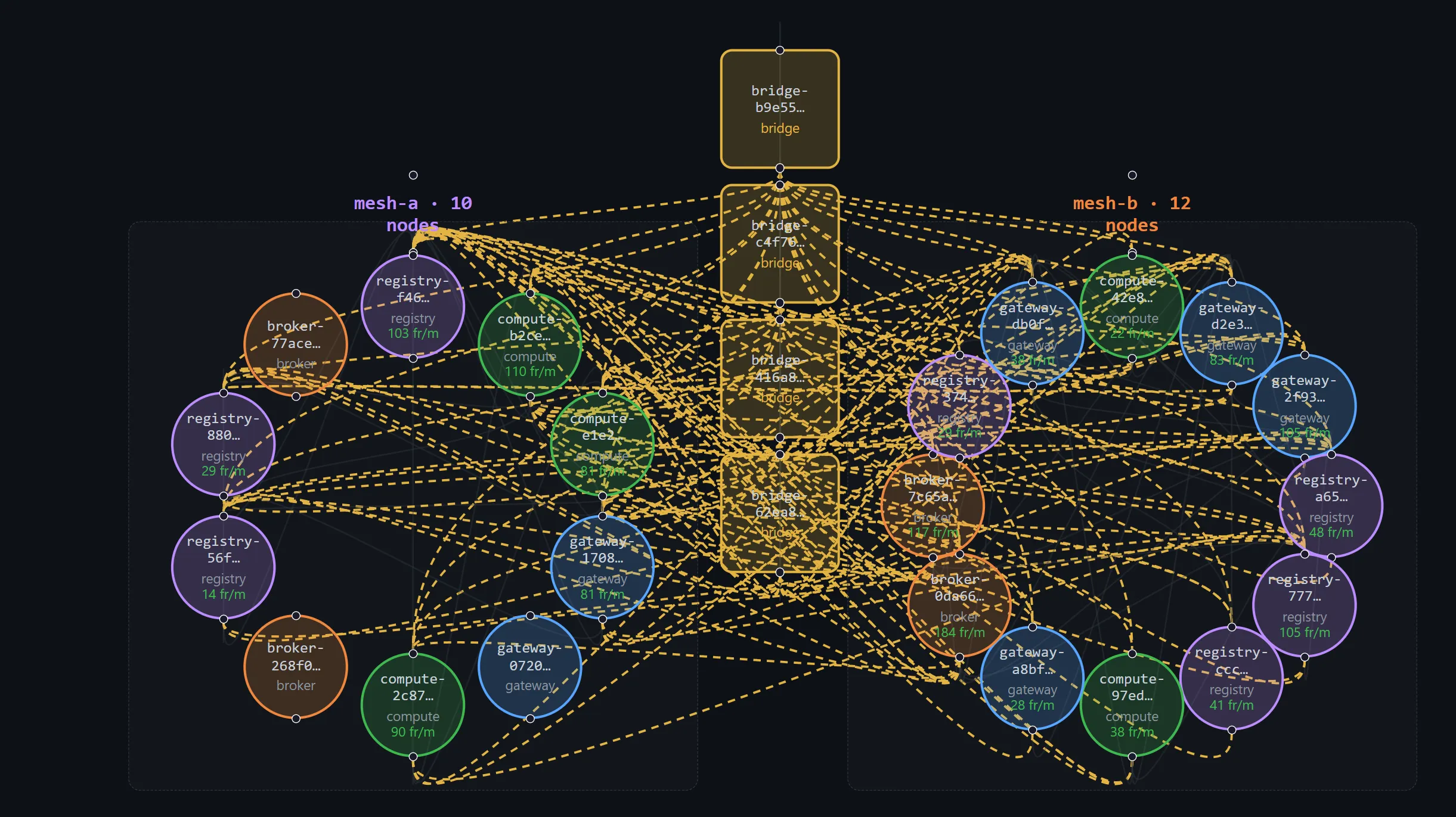
It is not a library you should take and run in production. It's a kit you can read while you're building your own. The bugs I paid for are now diffs you can study. The dashboard I built so I'd believe my own numbers is in there too — React, plain Vite, no framework. The flamegraph captures are in /profiles.
What's in the box
| Piece | What it does |
|---|---|
crates/mesh-node-base | The substrate. Identity, gossip emit loop, peer registry, LoadSampler (self-reported CPU/RAM), staleness pruner. Built on iroh-gossip 0.98. |
crates/mesh-transport | Thin layer over iroh's Endpoint. ALPN, mDNS toggle, bind addr, 30s idle timeout. |
crates/mesh-telemetry | OTLP/tracing init. Every node's spans land in Jaeger; receive-time staleness is local, not sender-side. |
admin-ui/ | React + Vite topology view. Live node grid, hub-and-leaf layout, CPU/RAM bars per node, kill button per card. The thing you stare at when you don't believe the numbers. |
broker / gateway / compute / registry / bridge | Example node types. Each one is a 10-line main.rs that calls NodeRuntime::new("type").run().await. From the substrate's perspective they're interchangeable. |
Stack: rust (substrate) · iroh 0.98 + iroh-gossip (QUIC + NAT traversal + Plumtree/HyParView) · tokio · opentelemetry → Jaeger · react + vite (UI).
The five engineering posts in this notebook walk through the work in order:
- Why I'm building a distributed mesh substrate in Rust — the architecture, the iroh choice, what I expected to break.
- When 18 nodes pegged my 80-core box at 100% — the first round of obvious wins (mDNS off, gossip interval up, INFO spans down). 100% → 35%.
- Flamegraphing your way out of "this can't possibly be right" — the
join_peersstorm that I almost rewrote the architecture to escape. 35% → 5%. - Four days into the soak, the RAM was still climbing — the slow leaks that only a long-running soak surfaces. Ghost connections, unbounded global maps, the staleness pruner that ties it together.
- Chaos-pass replaces tests-pass — 13 chaos primitives, 12 tests, 5-minute soak under continuous random chaos. All green.
What the kit is, and isn't
This is a learning artifact. It is not:
- A finished product. The streaming layer that sits on top of this substrate — the actual event-streaming app — isn't open yet. What you're reading is what's underneath it.
- A managed iroh integration. It's an opinionated set of patterns for using iroh-gossip in a long-running process. Different from a library — closer to a scaffold.
- Production-ready. I've run it on one box. I haven't run it across NATs, across regions, or at scale. The substrate is correct under the workload I've tested; it's not proven outside it.
It is:
- A documented diff trail. Every fix in the four engineering posts above corresponds to a commit in the repo. You can
git logyour way through the optimization arc. - A flamegraph dataset. The 2 GB
.foldedfiles that surfaced thejoin_peersstorm are in/profiles. Runinferno-flamegraphon them and you'll see the bug. - A dashboard you can read. The admin-ui code is short — maybe 800 lines of TypeScript. It joins the mesh as a passive observer and renders the topology live. Plain React, plain Vite, no state framework. Lift it if it helps.
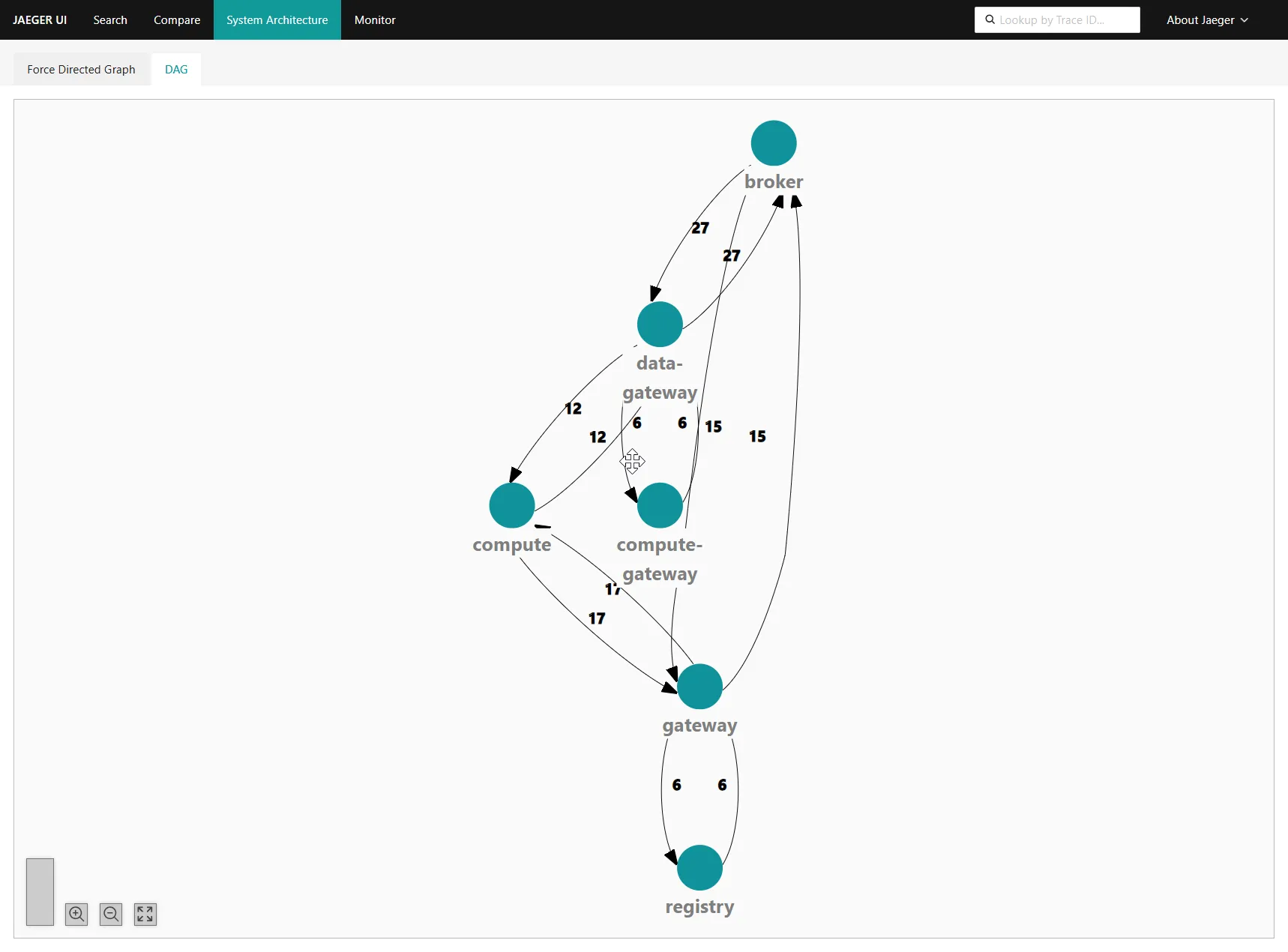
Telemetry is the second view of the same thing. Every span lands in Jaeger; the System Architecture DAG gives you the service-to-service call pattern without leaving the browser:
Numbers, before and after
| Metric | First canary | After five weeks |
|---|---|---|
| Host CPU (80-logical box, 18 nodes idle) | 100% | 5% |
| Per-node CPU avg | 0.83 cores | 0.05–0.10 cores |
| Per-node RAM avg | growing linearly | bounded at ~60 MB |
| Stable across 4-day soak | no — climbing on every axis | yes |
| Bugs I shipped in the first version | every single one in the four posts above | most fixed; one or two known sharp edges remain |
For comparison: a Bitcoin Core full node idles at 5–10% of one core. A Tor relay idles under 1%. The mesh substrate as it stands is competitive with both at this scale.
What I'd tell someone building one
I've said most of this in the four posts. Concentrated:
- The protocol probably isn't the bug. Measure first. I almost rewrote to a centralized-Controller architecture before checking. The flamegraph took 15 seconds to capture and made the question moot.
- Comments lie. Flamegraphs don't. Every CPU bug I found had a comment claiming the code was cheap. Trust the profile.
- Soak the substrate. A 30-second canary will not catch the bugs that take 4 days to surface. If the substrate is load-bearing, leave it running overnight before you build anything on it.
- Process-global state needs an owner. Every
DashMapthat lives for the process lifetime needs a clear answer to "what removes entries from this?" If the answer is "nothing, we just restart" — add a pruner before you ship. #[instrument]on an infinite loop is almost always wrong. The span never closes. The event queue grows forever. Decorate the work inside the loop, not the loop itself.
What's next
The streaming layer is what comes next, built on the substrate I just spent five weeks debugging — event streaming, multi-tenant by topic, nodes across networks — riding on a foundation that now actually idles when it has nothing to do. But there turned out to be one more leak hiding in the substrate first, which is where this notebook goes from here.
If you're building on iroh, fork freely. If you find a bug I missed, open an issue. The repo will keep moving.