
Kill by message, not by ownership — and a node is a state
The console could kill nodes. Sort of. It worked by holding the OS child handle of every process it had spawned and calling TerminateProcess — which means a console could only kill its own spawns, not a node it merely saw in another mesh. That's backwards for a self-aware fleet: which OS process happens to own a node should have nothing to do with who can operate on it.
A kill is a message
So a kill became a control op. Any participant — including a console in a different mesh — sends the target a Shutdown frame over the mesh (direct or via the relay). The target receives it, shuts itself down gracefully (emits node.stopping, broadcasts its own tombstone), and exits. The caller resolves the target's address from what it can already see — its own gossip, the cross-mesh backbone directory, or its spawn registry — and dials it. No process ownership anywhere.
The proof: from the mesh1 console, kill a mesh2 gateway the mesh1 console never spawned. The gateway process dies, and it disappears from both consoles immediately. mesh1 commanded it; it didn't own it.
A node is a node
While wiring that up, a sharper question: a console is in a mesh — why doesn't its mesh show up to other consoles? Because only gateways published a mesh's summary to the backbone, and the console was a subscribe-only observer. So a mesh whose only node was its console was invisible cross-mesh.
A node is a node. The console now publishes too — it's a backbone publisher candidate alongside gateways, and the soft lease still elects exactly one publisher per mesh. So every mesh advertises itself, even a bare console. Both consoles show both meshes whether or not either has a gateway — and I test that with a deliberately non-balanced fleet, because a symmetric one can pass on coincidence.
A node is a state
The tombstone proved a nice pattern: broadcast "this node is gone" as an event and everyone evicts instantly — no waiting for a timeout. The natural generalization is to make the whole lifecycle an event. Not a binary join/leave, but a state:
Joining · Alive · Degraded · Updating · Draining · Leaving · Dead
A node publishes its own lifecycle on every transition; Leaving is the old fast-delete. The one it can't publish is Dead — a crashed node announces nothing — so Dead is what observers assign when a node vanishes without a Leaving. The operator gets the difference for free: "left cleanly" vs "crashed" vs "just rolling an update," instead of everything collapsed into "gone." Live, the topology colors each node by state — a broker mid-Draining, another Degraded and pinned at 100% CPU, the rest Alive:
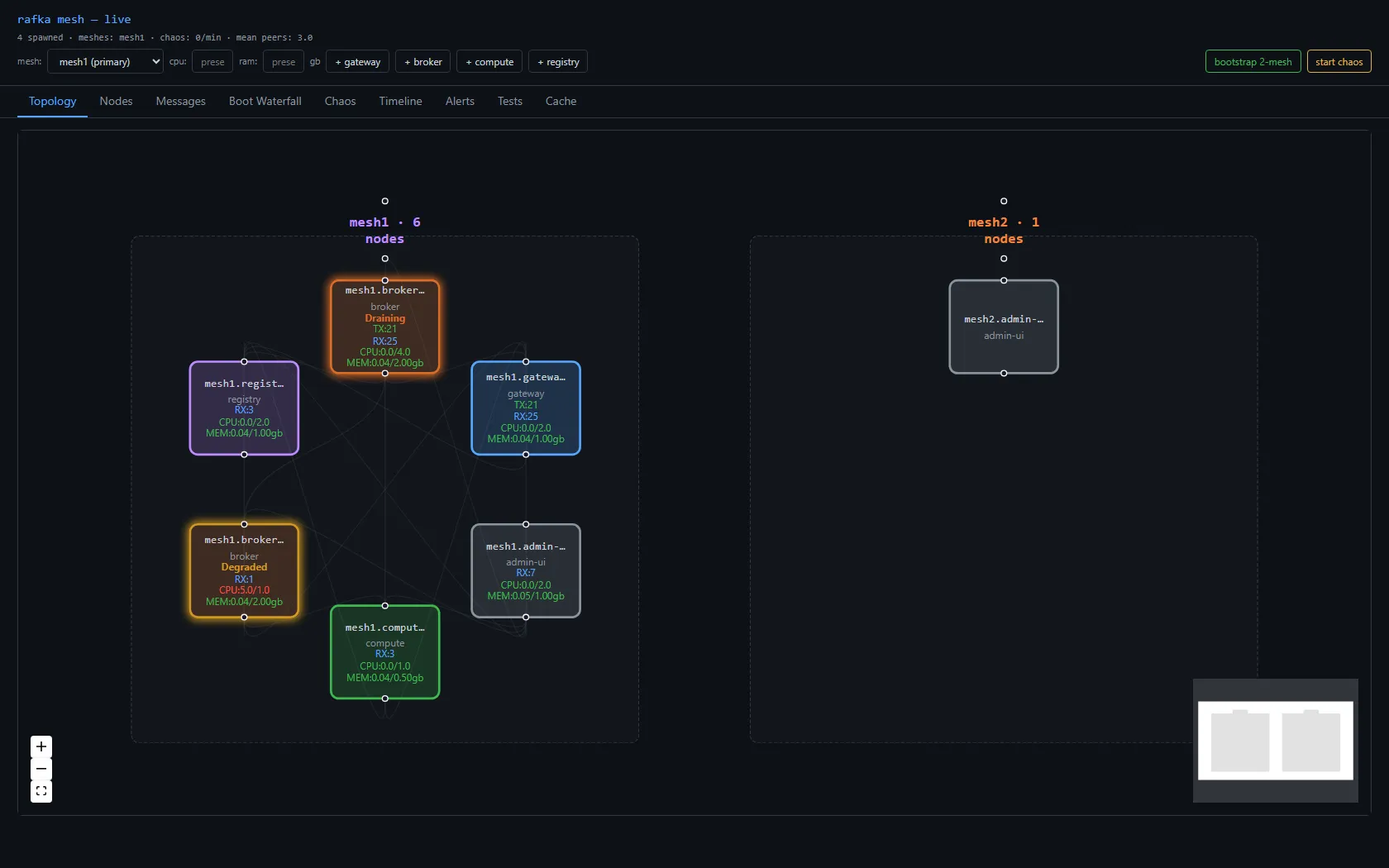
Each node card carries the controls that drive those transitions directly — drain, upd (update), resume, and kill — so an operator moves a node through its lifecycle by message, from any console:
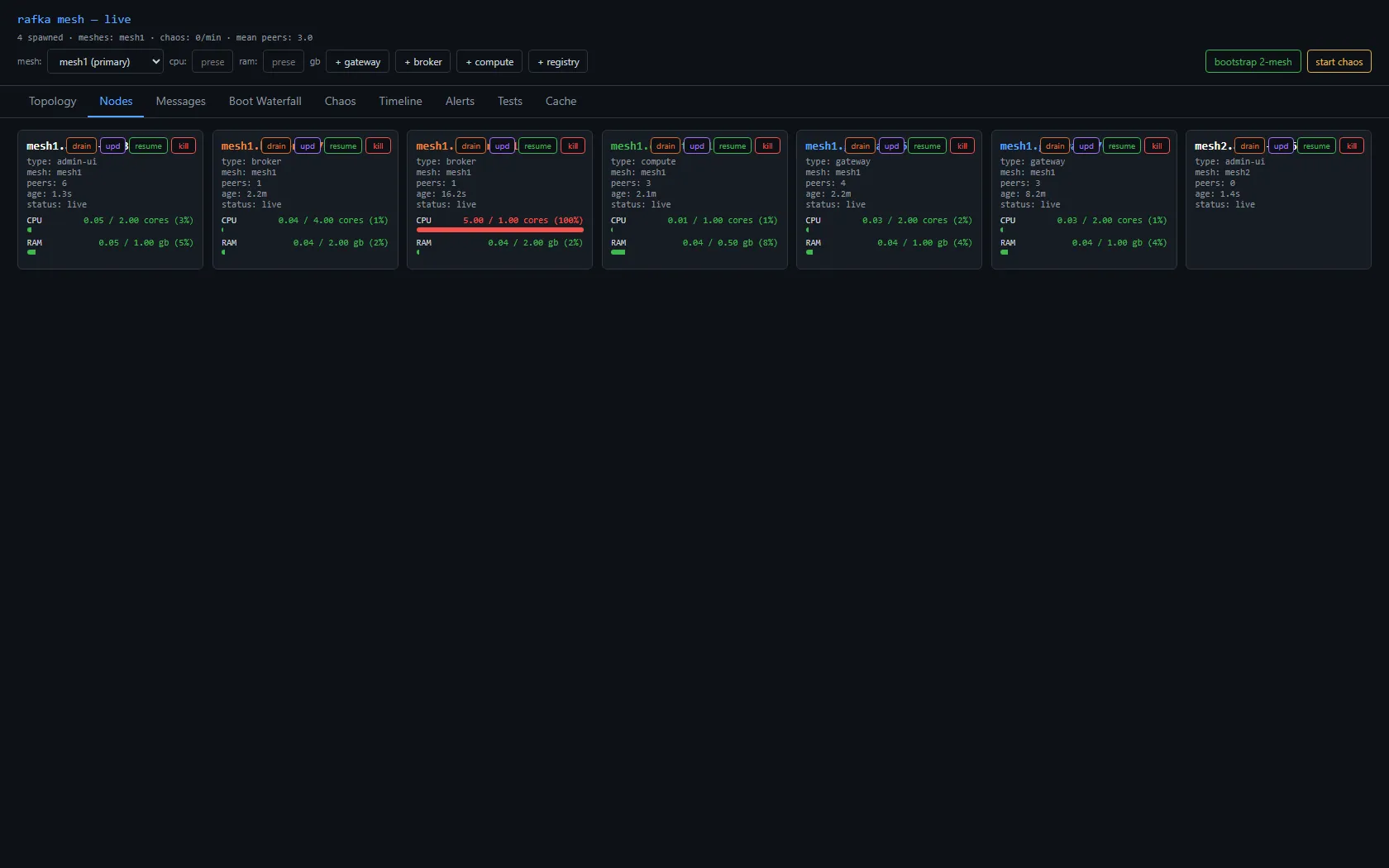
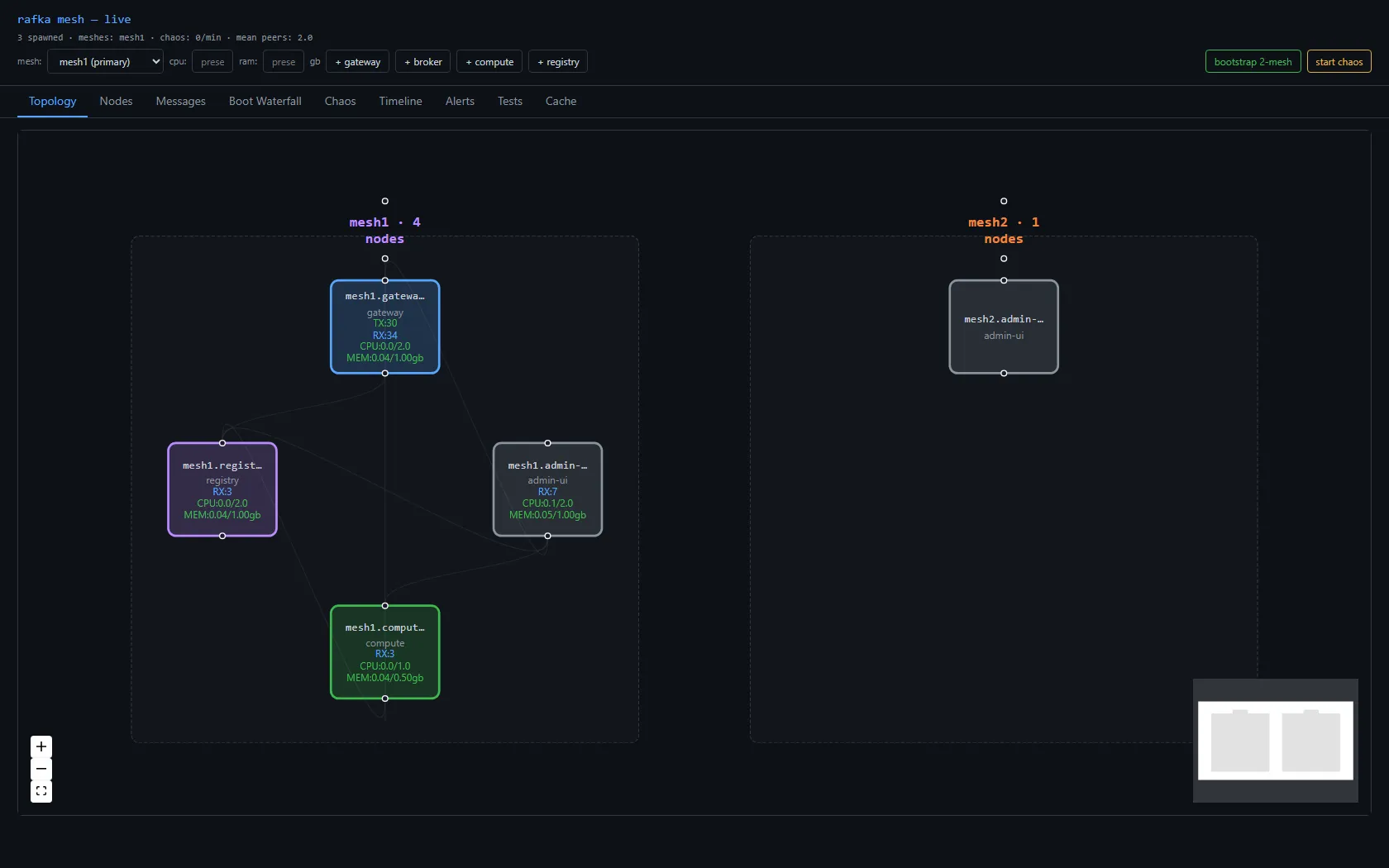
An honesty note, because the order matters. When I first wrote this lifecycle up, I wrote it in the present tense as if it had all shipped — it hadn't. At that point only Leaving/Dead eviction was real (the tombstone). Updating/Draining had no trigger you could reach, and nothing fired on a state change — it was the design, not the system. It became real afterward, in pieces: the enum wire change and observer-inferred Dead first; then a SetState control op to actually drive Updating/Draining; and last, the durable per-transition event — a node.state_changed span on every self-state change — which is what finally makes "publishes its lifecycle on every transition" a true sentence instead of an aspiration. Proven end to end: one node walking Joining → Alive → Updating → Draining as a clean span trail, plus Leaving (kill) and Dead (crash) as distinct tombstone sources. After it leaves or dies, observers evict it and the topology settles back to what's actually alive:
The most expensive lesson (and it wasn't in the mesh)
For hours the cross-mesh view looked broken, and I nearly wrote off two earlier sprints as defective. They weren't. I was testing stale binaries. On Windows a running .exe is file-locked, so rebuilding while a node runs silently leaves the old binary in place — and worse, the console spawns its child nodes from target/debug while I'd been building --release. So the nodes that actually ran were ancient code, broadcasting a wire format the new code couldn't decode. A one-line Get-Process | Select Path showed it instantly, once I stopped trusting "the build succeeded" and started gating on "is the binary I'm about to run actually newer than the source I changed?"
The mesh code was right the whole time. The discipline — kill everything, rebuild, verify the binary is fresh, then conclude — is the part that wasn't. That one's framed on the wall now.
What I'd tell a team
- Authority is a message, not a handle. Tie "who can operate on a node" to a process handle and you've quietly coupled control to deployment topology. A control frame any authorized participant can send decouples them — and works across the relay, which a process handle never could.
- Model lifecycle as a state, and let
Deadbe inferred. A node can announce every transition except its own crash. Make "vanished without a goodbye" meanDead, and the operator gets "crashed vs left vs updating" for nothing. - Write the changelog in the tense that's true. I described a lifecycle as shipped when it was designed, and had to correct it. Present tense is a claim; if the event doesn't fire yet, say "designed," not "does."
- Gate on binary freshness, not build success. "The build succeeded" and "the thing I'm about to run is the thing I just built" are different sentences. On Windows especially, verify the second one before you conclude anything from a test.